文章以 redis 5.0 版本的源码作为基础,高版本可能有所不同
redis 中的 dict 其实与 java 中的 map 实现大差不差,都是基于哈希表实现,使用拉链法解决哈希冲突的问题,在达到装载因子预订值时自动扩展内存(重哈希)。
# dict 的结构
dict 总体结构图:
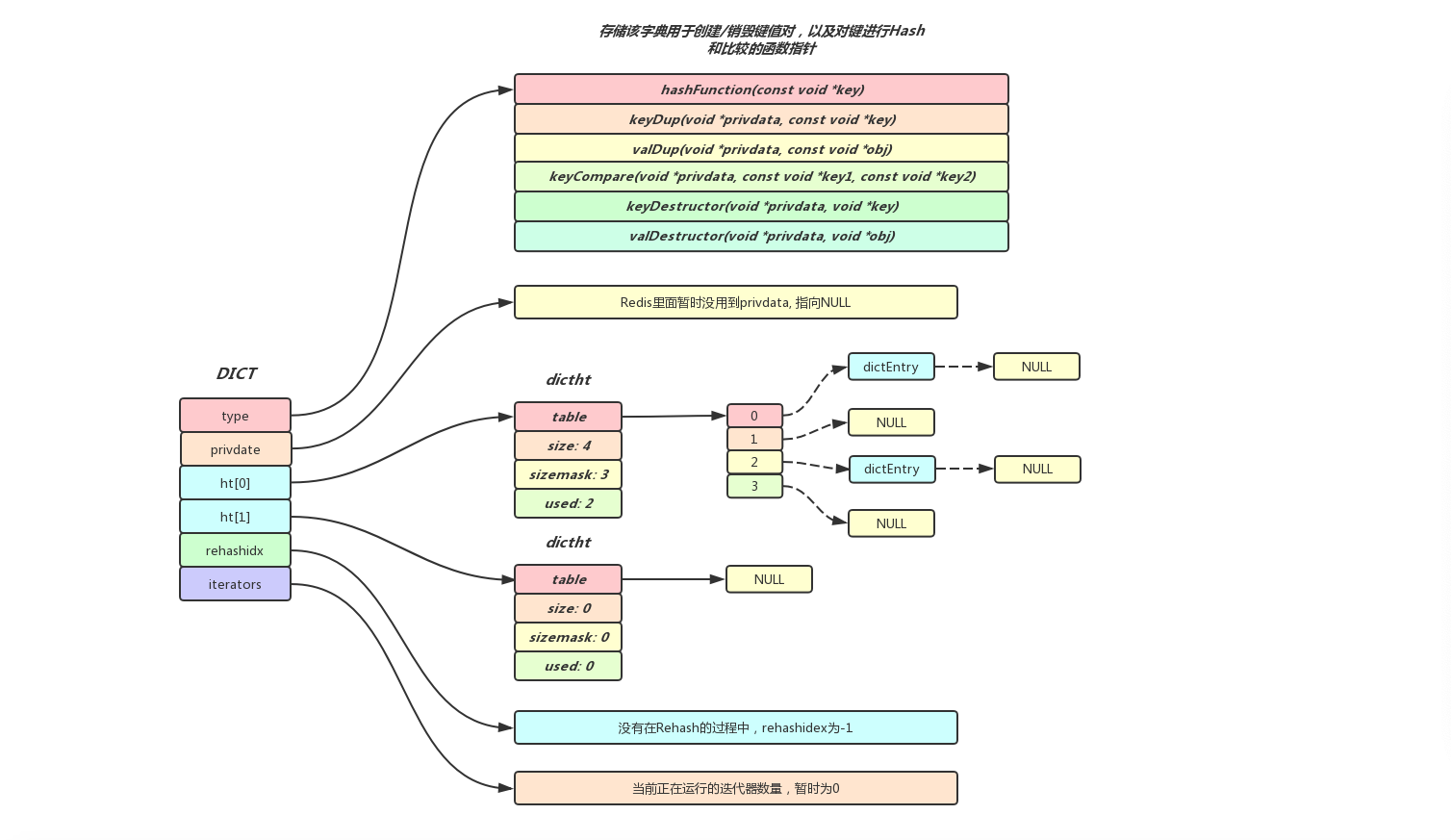
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
dictType *type:定义了一些内部会使用到的方法,例如 hash 函数,key 比较函数,其实就类似于 java 的接口。void *privdata:保存了需要传给特定键值对函数的可选参数dictht ht[2]:hash 表,之所以有两个 hash 表,主要是用来进行 rehash。在没有 rehash 的时候,ht [1] 大小为 0;在 rehash 的时候,为 ht [1] 分配空间,将 ht [0] 中的 entry 迁移至 ht [1]。long rehashidx:记录 rehash 过程中 ht [0] 进行到了哪一个 bucket,没有 rehash 的情况下固定为 - 1unsigned long iterators:外界当前迭代该 Dict 迭代器的个数
# dictType
typedef struct dictType {
uint64_t (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
hashFunction:hash 函数keyDup:key 拷贝函数valDup:val 拷贝函数keyCompare:key 比较函数keyDestructor:销毁 keyvalDestructor:销毁 value
# dictht
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
dictEntry **table:hash 表,存放一个数组的地址,数组存放着哈希表节点 dictEntry 的地址unsigned long size:hash 表的大小unsigned long sizemask:用于将 hash 值映射到 table 的位置索引,总是等于(size-1)unsigned long used:记录 entry 的数量
# dictEntry
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
entry 的结构就比较简单了,相当于一个链表。
void *key:keyunion {} v:保存 value,可以看到不只有一个void *val,这是为了在不同情况下用不同的类型来保存数据,更好的利用内存struct dictEntry *next:next 指针
# dict 的创建过程
/* Create a new hash table */
dict *dictCreate(dictType *type,
void *privDataPtr)
{
dict *d = zmalloc(sizeof(*d));
_dictInit(d,type,privDataPtr);
return d;
}
/* Initialize the hash table */
int _dictInit(dict *d, dictType *type,
void *privDataPtr)
{
_dictReset(&d->ht[0]);
_dictReset(&d->ht[1]);
d->type = type;
d->privdata = privDataPtr;
d->rehashidx = -1;
d->iterators = 0;
return DICT_OK;
}
/* Reset a hash table already initialized with ht_init().
* NOTE: This function should only be called by ht_destroy(). */
static void _dictReset(dictht *ht)
{
ht->table = NULL;
ht->size = 0;
ht->sizemask = 0;
ht->used = 0;
}
主要就是进行分配内存,然后设置初始化值。
# dict 的 rehash
和 Java 的 HashMap 一样,随着数量的增加,也会产生问题:随着数据越来越多,冲突的次数也就越来越多,单链表的长度就会过长,此时的查询效率就变得很差。
Java 中的解决方式为:
- 链表长度过长时,先检查总桶数是否大于 64,如果小于,先扩容,如果大于,转成红黑树
- 当使用的桶数 >= 总桶数 * 负载因子时,进行扩容
其中负载因子在 Java 中固定设置为了 0.75
redis 虽然也使用了负载因子,但是稍有不同。redis 中的负载因子计算方式为 dictht.used/dictht.size,即使用的 entry 数量 /hashTable 长度。
判断是否需要扩容的代码:
/* Expand the hash table if needed */
static int _dictExpandIfNeeded(dict *d)
{
/* Incremental rehashing already in progress. Return. */
if (dictIsRehashing(d)) return DICT_OK;
/* If the hash table is empty expand it to the initial size. */
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
/* If we reached the 1:1 ratio, and we are allowed to resize the hash
* table (global setting) or we should avoid it but the ratio between
* elements/buckets is over the "safe" threshold, we resize doubling
* the number of buckets. */
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
return dictExpand(d, d->ht[0].used*2);
}
return DICT_OK;
}
- 如果 ht [0] 所指向的 HashTable 大小为 0 则扩容
- HashTable 负载因子大于等于 1,即 ht.used>=ht.size
- HashTable 负载因子大于 5,即 ht.used/ht.size>dict_force_resize_ratio,这里的 dict_force_resize_ratio 是固定值 5
# 参考
- redis-dict (axlgrep.github.io)
- 字典 — Redis 设计与实现 (redisbook.readthedocs.io)
- Redis 内部数据结构详解 (1)——dict - 铁蕾的个人博客 (zhangtielei.com)
- redis/src/dict.h at 5.0 · redis/redis (github.com)